
MySQL indexing works by storing specific data columns in a separate sorted data set that can be used to quickly locate relevant rows in a large table without the need to scan the whole table.
This works exactly like the index in a book. If you want to find a specific chapter in the book, you can either go through the book page by page until you reach the chapter you want, or you can look in the index to see what page the chapter is at, and go directly to this page.
Indexes are not specific to MySQL, in fact, MySQL uses an index type called a B+ Tree. This is a data structure that has been used for years to build indexes in all kinds of software due to how fast it allows us to search the data. So to understand how MySQL indexing works internally, we should explain the B+ Tree. But first, let’s see how MySQL finds data without an index.
Full table scan
Let’s consider the following scenario: You have a table of customers that includes only 3 columns (id, name, and phone_number)
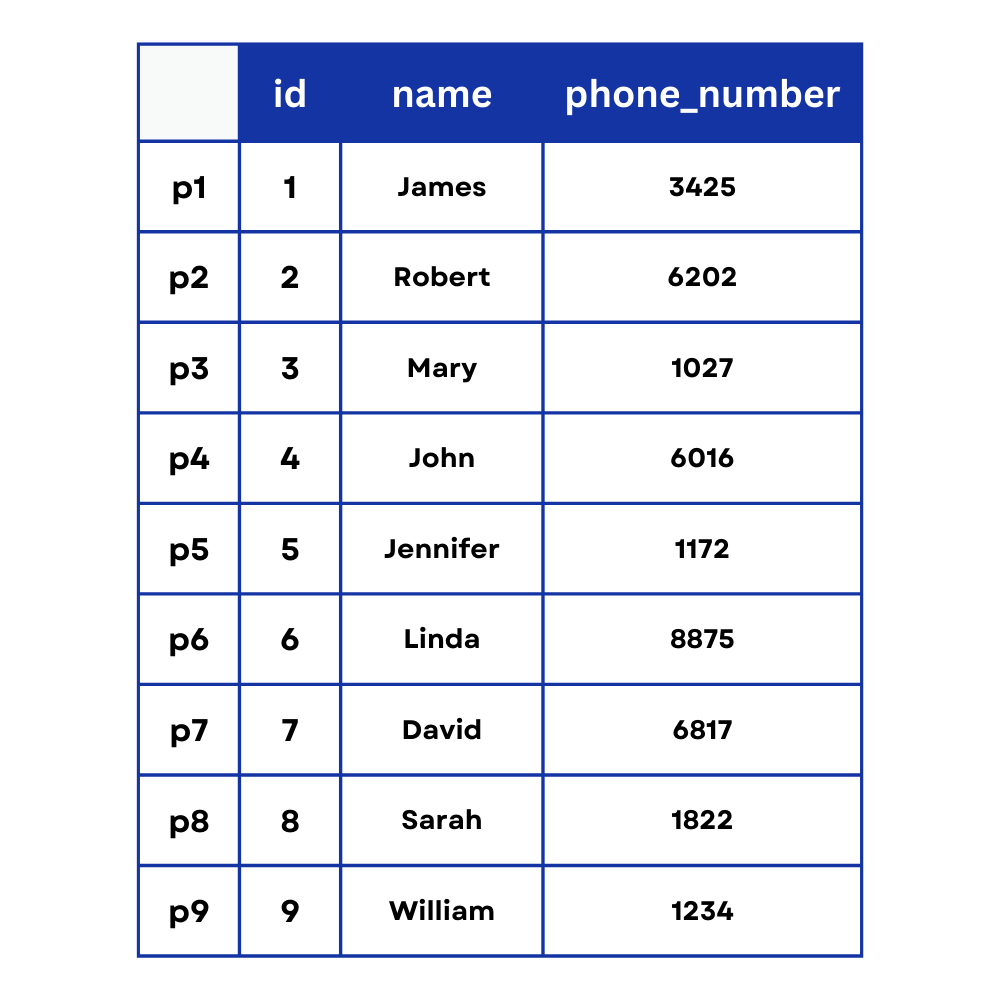
What’s this first column with no name, you ask? This is the position of the row on the physical disk. Remember, MySQL stores data on the computer disk whether it’s an SSD or HDD. So every piece of data in the table lies in a specific address on that disk.
Now, If I wanted to get the customer with the phone number 1822, I would run a query like this:
SELECT * FROM customers WHERE phone_number = 1822;Since there is no index on the phone_number column, MySQL will have to run a full scan. It will start reading from position p1 on the disk, it reads an ID of 1, a name of “James”, and a phone number of 3425, which is not the number it’s looking for. It will then proceed to read p2, p3, all the way to p8 where the requested phone number is stored.
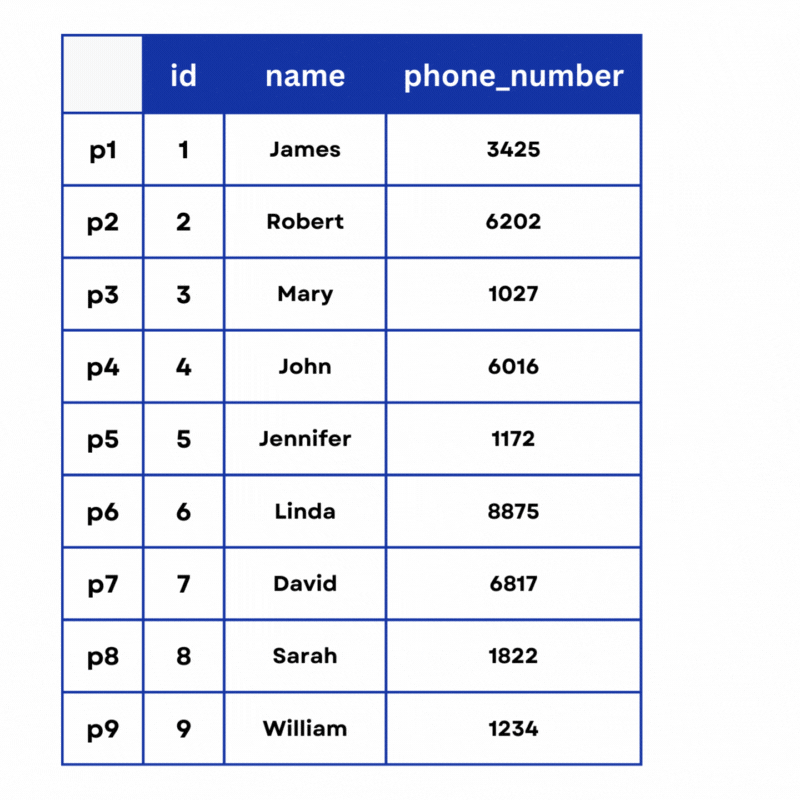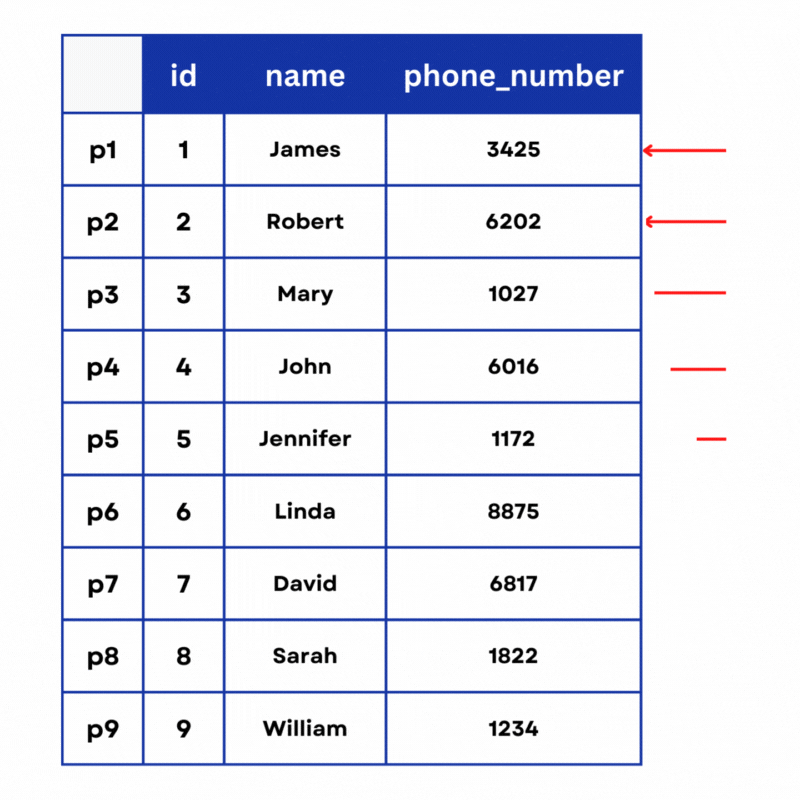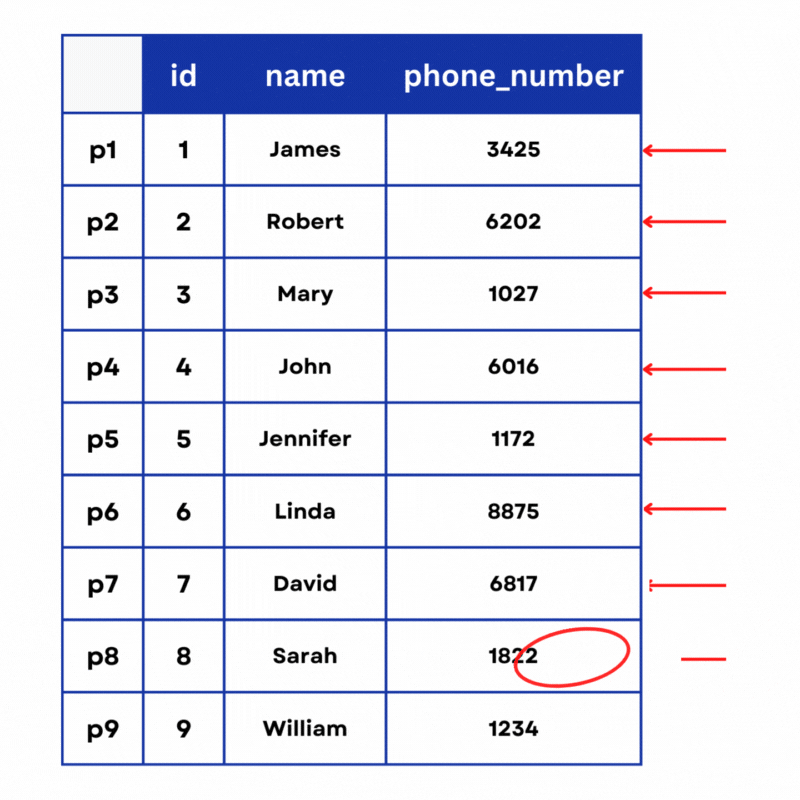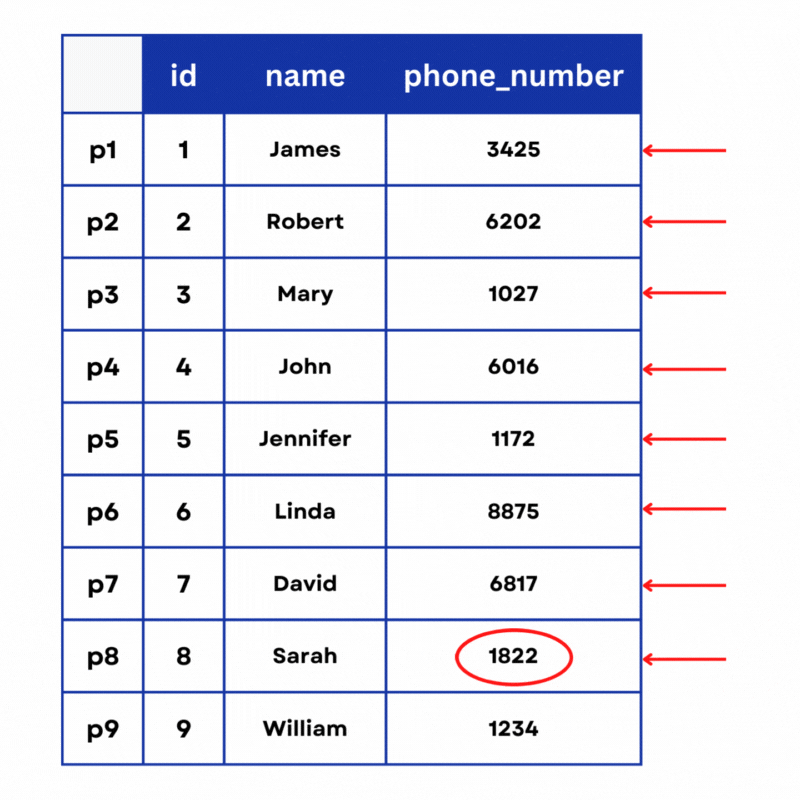
This operation took 8 steps. And if the value that we are looking for was at position 100 on the disk, it would have taken 100 steps. This is why we say that a full table scan has a time complexity of O(n), which means that for n number of entries the operation will be n steps long. This is not a problem if we have hundreds or even thousands of rows in a table. But once we get to millions and tens of millions of rows, queries become significantly slower.
How MySQL creates and uses the index
Now let’s instruct MySQL to create an index on the column phone_number:
CREATE INDEX phone_number_index ON customers (phone_number);What MySQL does in the background is that it builds a B+ Tree data structure that includes all the values from the phone_number column. Which will look something like this:
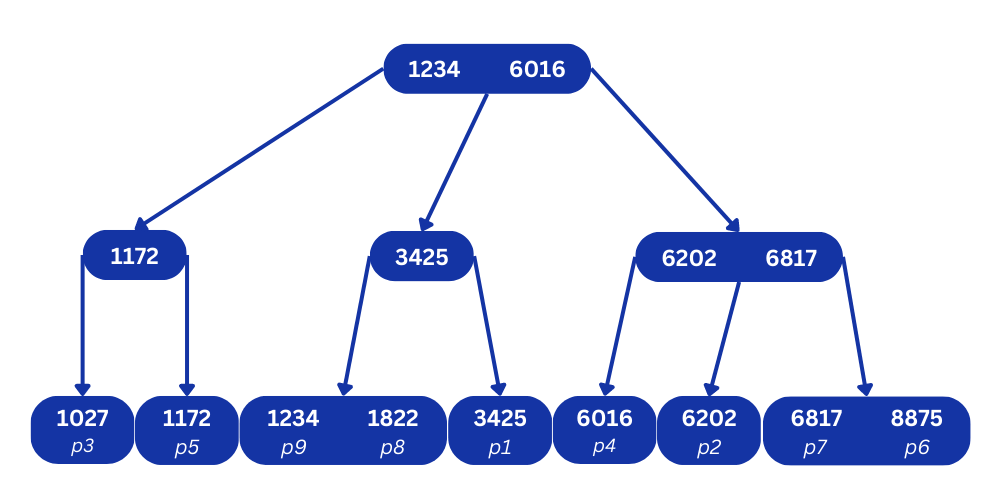
As you can see in the tree above:
- It starts with one root node containing one or more values that fall between the minimum and maximum values in the data set.
- It branches down to smaller values on the left and greater values on the right.
- The bottom level of the tree, which consists of the so-called leaf nodes, contains all the values in the data set sorted in ascending order.
Now we can run the same query again to search for phone number 1822. This time, MySQL will not start by reading the table. Instead, it will start by reading the tree and going through the nodes starting from the root node. It will follow these simple rules:
- If the value it’s looking for is less than the current node, it will go down to the left branch.
- If the value is greater than the current node, it will go down to the right branch.
- If the value is in between the 2 values in the node, it will go down the middle branch.
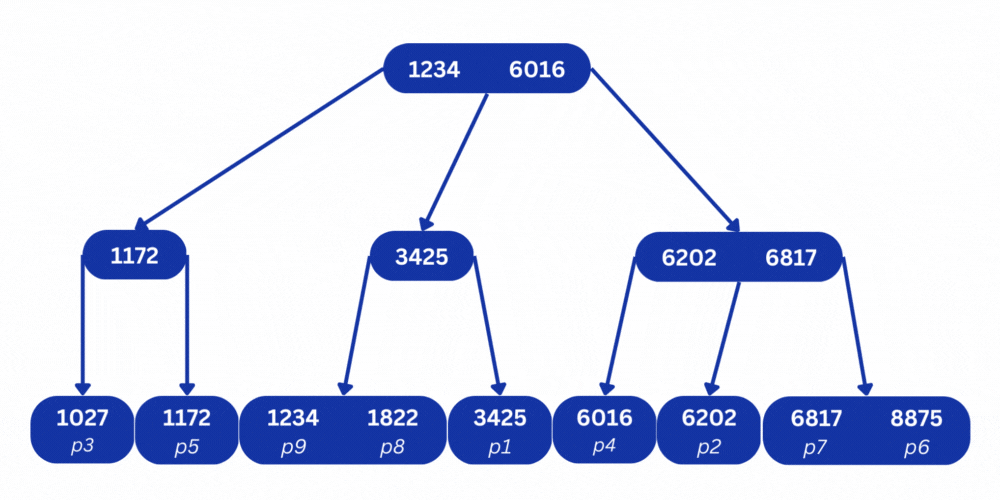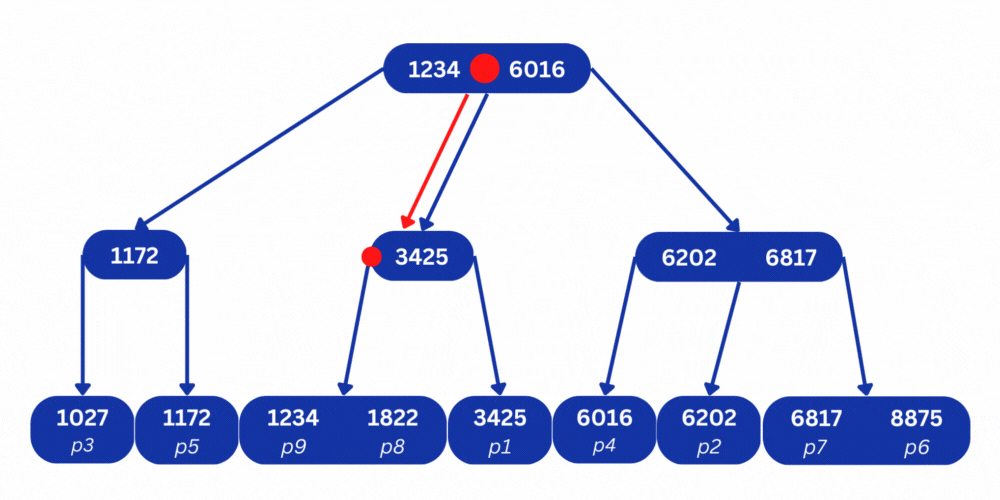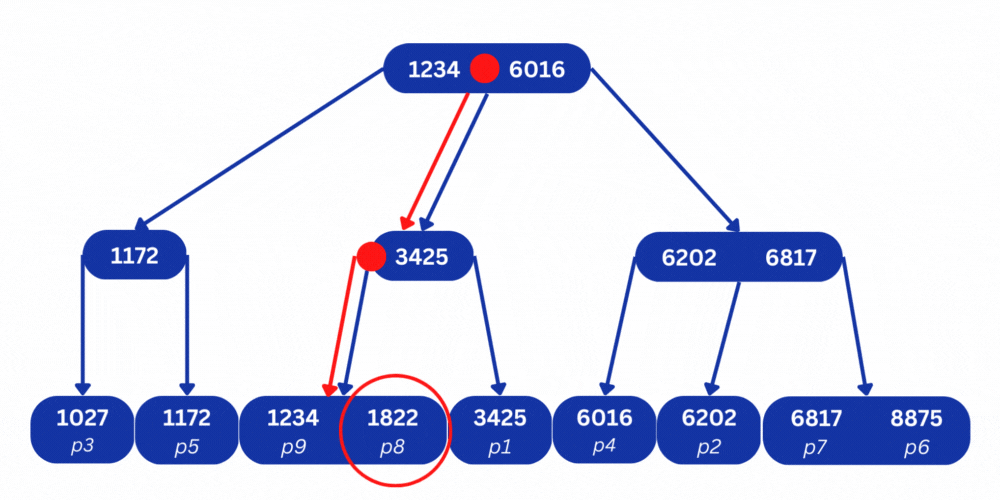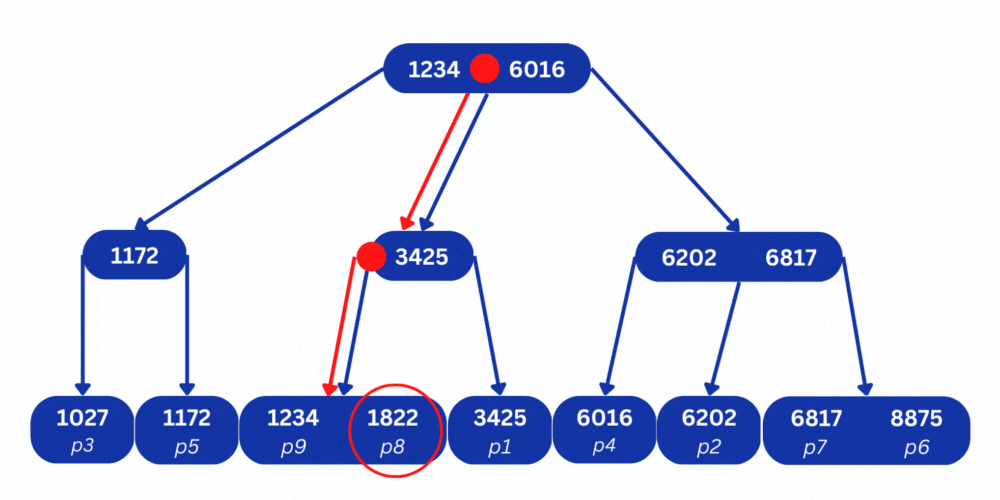
So in this case, MySQL will branch down to the middle and then down to the left to find the phone number 1822. It can then take the position p8 from the node and seek directly to this address in the disk to read the full row that contains the phone number along with other information.
Using the B+ tree index, the search operation took only 2 steps, while without the index it took 8 steps. And although this doesn’t seem like a huge improvement, the performance gains become more significant as the number of rows in the table grows. The B+ tree has a time complexity of O(log n), which means that a table with a million rows can be represented in a tree that is only 13 levels deep, which makes searching for values super fast.
The following table shows the number of steps required to find a value in a table with and without an index.
| Rows | Steps required with no index | Steps required with index |
|---|---|---|
| 1,000 | 1,000 | 7 |
| 1,000,000 | 1,000,000 | 13 |
| 1,000,000,000 | 1,000,000,000 | 19 |
As you can see, exponential growth in the number of rows causes a very minimal increase in the number of steps required to find a value using an index. This is why an index is essential when running queries on large data sets.
Final Notes
The B+ Tree is not the only data structure used for indexing. In fact, MySQL uses another type of index called Hash index. But it’s only used in the MEMORY engine, which is not commonly used. Also, other types of software use various data structures as indexes. However, the idea is basically the same. An index simply organizes a subset of the data in a quickly accessible format that can be used to locate the position of an entry on the disk without having to scan through the whole data set.
It’s also important to keep in mind that an index is not an all-good solution that will magically solve all your database problems. It comes at a cost, as with almost everything in software design. While indexes make searches super fast, they make updates to the data slower. Without an index, an update will have to be applied only to the data table. But if an index exists, MySQL also has to update the index with the new value. And depending on the new value and the current state of the B+ tree, updates can require relatively expensive rebuilds of tree branches.
So while indexes are beneficial more often than not, you have to consider the nature of your specific data set before using them.